Some days ago we did an optimized version of our series with Spring Web, now we will try to improve further the numbers using a reactive platform, for this we will use Spring WebFlux and R2DBC.
Here, as a reference, are the numbers that we got so far :
| C. Users | Pods | ART | TPS | Max CPU | Max MEM | Service |
|---|---|---|---|---|---|---|
| 1 | 1 | 39.16 | 25.49 | 403 | 474 | 01 Base |
| 1 | 1 | 34.61 | 28.85 | 209 | 252 | 02 Spring Web |
| 10 | 1 | 570.47 | 16.73 | 916 | 487 | 01 Base |
| 10 | 1 | 111.61 | 85.53 | 626 | 350 | 02 Spring Web |
| 25 | 3 | 1615.82 | 14.72 | 1049 | 1454 | 01 Base |
| 25 | 1 | 266.03 | 89.44 | 686 | 369 | 02 Spring Web |
| 50 | 5 | 3190.98 | 14.89 | 1351 | 2499 | 01 Base |
| 50 | 3 | 1982.03 | 23.95 | 774 | 1060 | 02 Spring Web |
01 Base = Java 8 - Spring Boot 2.2.2 - Spring Web - Spring Data JDBC default settings, unoptimized
02 Spring Web = Java 11 - Spring Boot 2.2.2 - Spring Web - Spring Data JDBC optimized
Bootstrapping a Spring Boot application
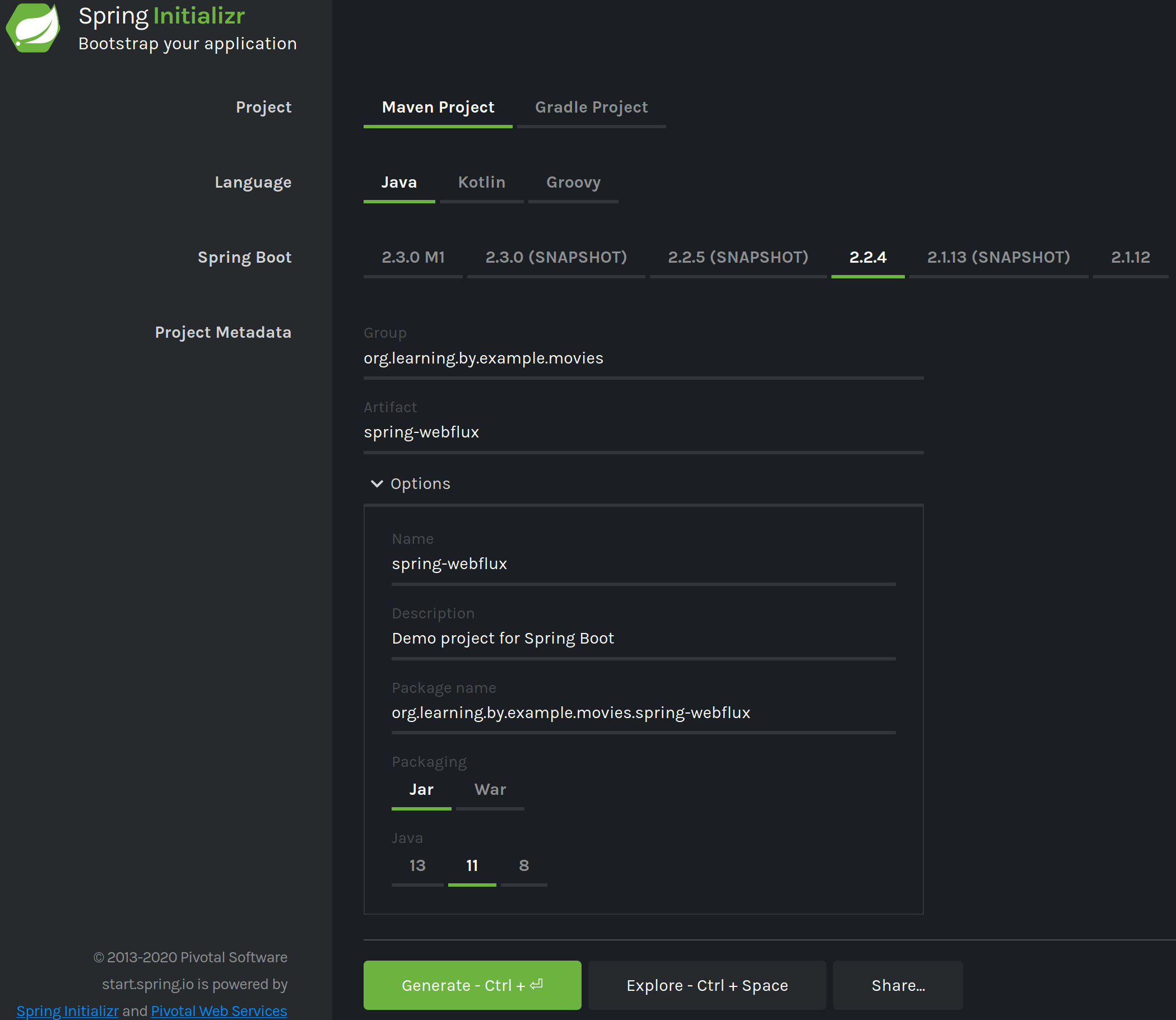
We are going to use Spring Initializr https://start.spring.io/ to quickly bootstrap our application.
We will create a Maven Project using Java 1 and Spring Boot version 2.2.4, we will set the Group to be org.learning.by.example.movies, and the Artifact to spring-webflux, the rest of the values should be automatically populated.
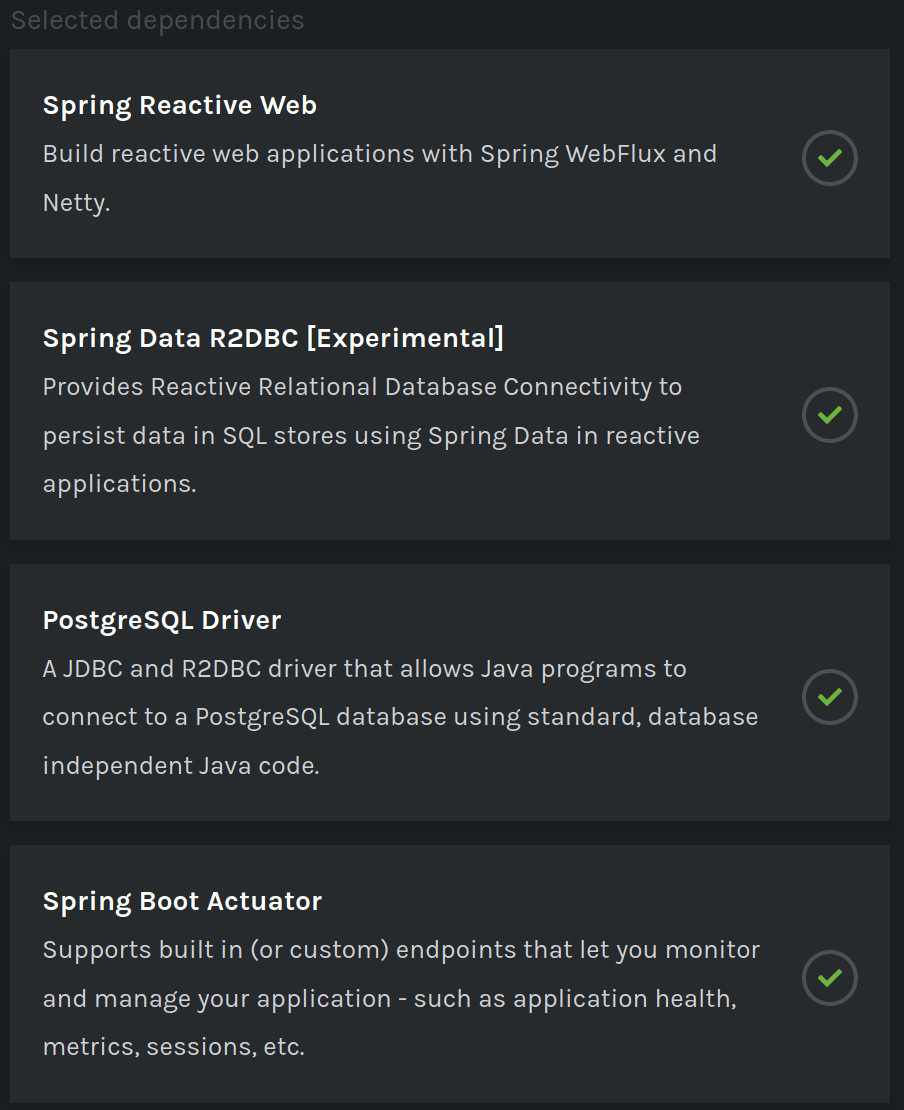
For dependencies we will search and add :
- Spring Reactive Web
- Spring Data R2DBC [Experimental]
- PostgreSQL Driver
- Spring Boot Actuator
Now we will click on Generate to download our zip file : spring-webflux.zip, we will uncompress it and leave it ready to be opened with our favorite IDE.
Creating a Reactive repository
First we will create our POJO that we will use to retrive a movie.
package org.learning.by.example.movies.springwebflux.model;
import java.util.List;
import java.util.Objects;
public class Movie {
private final Integer id;
private final String title;
private final Integer year;
private final List<String> genres;
public Movie(final Integer id, final String title, final Integer year, List<String> genres) {
this.id = id;
this.title = title;
this.year = year;
this.genres = genres;
}
public Integer getId() {
return id;
}
public String getTitle() {
return title;
}
public Integer getYear() {
return year;
}
public List<String> getGenres() {
return genres;
}
}This is identical as we did in our JDBC example.
Now we will create our reactive repository.
package org.learning.by.example.movies.springwebflux.repositories;
import org.learning.by.example.movies.springwebflux.model.Movie;
import org.springframework.data.r2dbc.repository.Query;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.stereotype.Repository;
import reactor.core.publisher.Flux;
@Repository
public interface MoviesRepository extends ReactiveCrudRepository<Movie, Integer> {
@Query(value = "SELECT \n" +
" m.id, m.title, m.genres \n" +
" FROM \n" +
" movies as m \n" +
" WHERE :genre = ANY(string_to_array(LOWER(m.genres),'|')) \n")
Flux<Movie> findByGenre(String genre);
}This is very similar of the JDBC repository that we create before.
Now we need to create a converter.
package org.learning.by.example.movies.springwebflux.converter;
import io.r2dbc.spi.Row;
import org.learning.by.example.movies.springwebflux.model.Movie;
import org.springframework.core.convert.converter.Converter;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
@Component
public class MovieReadConverter implements Converter<Row, Movie> {
// Without escape characters this pattern ins : (.*) \((\d{4})\)
// ( = START GROUP 1
// .* = any set of characters
// ) = END GROUP 1
// = space
// \( = the character (
// ( = START GROUP 2
// d{4} = four digits, ex 1945
// ) = END GROUP 2
// \) = the character )
final static Pattern TITLE_YEAR_PATTERN = Pattern.compile("(.*) \\((\\d{4})\\)");
@Override
public Movie convert(Row row) {
final String rowTile = row.get("title", String.class);
final String realTitle;
final int year;
final Matcher matcher = TITLE_YEAR_PATTERN.matcher(Objects.requireNonNull(rowTile));
if (matcher.find()) {
realTitle = matcher.group(1);
year = Integer.parseInt(matcher.group(2));
} else {
realTitle = rowTile;
year = 1900;
}
final String[] genres = Objects.requireNonNull(row.get("genres", String.class)).split("\\|");
final List<String> genresList = Arrays.stream(genres).filter(
genre -> !genre.isEmpty()
).collect(Collectors.toList());
final int id = Objects.requireNonNull(row.get("id", Integer.class));
return new Movie(id, realTitle, year, genresList);
}
}This is doing almost what our mapper was doing for JDBC.
Next we will need to create a ConfigurationProperties to have our database configuration.
package org.learning.by.example.movies.springwebflux.datasource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@ConfigurationProperties("movies-datasource")
public class DataSourceProperties {
private String protocol;
private String credentials;
private String host;
private Integer port;
private String database;
private Boolean readOnly;
private PoolConfig pool;
public String getProtocol() {
return protocol;
}
public void setProtocol(String protocol) {
this.protocol = protocol;
}
public String getCredentials() {
return credentials;
}
public void setCredentials(String credentials) {
this.credentials = credentials;
}
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public Integer getPort() {
return port;
}
public void setPort(Integer port) {
this.port = port;
}
public String getDatabase() {
return database;
}
public void setDatabase(String database) {
this.database = database;
}
public Boolean getReadOnly() {
return readOnly;
}
public void setReadOnly(Boolean readOnly) {
this.readOnly = readOnly;
}
public PoolConfig getPool() {
return pool;
}
public void setPool(PoolConfig pool) {
this.pool = pool;
}
public static class PoolConfig {
public int getMinConnections() {
return minConnections;
}
public void setMinConnections(int minConnections) {
this.minConnections = minConnections;
}
public int getMaxConnections() {
return maxConnections;
}
public void setMaxConnections(int maxConnections) {
this.maxConnections = maxConnections;
}
private int minConnections;
private int maxConnections;
}
}This is very similar to our JDBC example however we are not use a JDBC string so will be set the host, port and database in separate variables.
Finally we will setup our data base configuration.
package org.learning.by.example.movies.springwebflux.datasource;
import io.r2dbc.spi.ConnectionFactories;
import io.r2dbc.spi.ConnectionFactory;
import io.r2dbc.spi.ConnectionFactoryOptions;
import io.r2dbc.spi.Option;
import org.learning.by.example.movies.springwebflux.converter.MovieReadConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.convert.converter.Converter;
import org.springframework.data.r2dbc.config.AbstractR2dbcConfiguration;
import org.springframework.data.r2dbc.convert.R2dbcCustomConversions;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import static io.r2dbc.pool.PoolingConnectionFactoryProvider.*;
import static io.r2dbc.spi.ConnectionFactoryOptions.*;
@Configuration
public class MoviesDataSource extends AbstractR2dbcConfiguration {
final DataSourceProperties dataSourceProperties;
final MovieReadConverter movieReadConverter;
final String userName;
final String password;
MoviesDataSource(final DataSourceProperties dataSourceProperties, final MovieReadConverter movieReadConverter) {
super();
this.dataSourceProperties = dataSourceProperties;
this.movieReadConverter = movieReadConverter;
final String credentials = dataSourceProperties.getCredentials();
this.userName = getCredentialValue(credentials, "username");
this.password = getCredentialValue(credentials, "password");
}
private String getCredentialValue(final String credentials, final String value) {
final Path path = Paths.get(credentials, value);
try {
return new String(Files.readAllBytes(path));
} catch (Exception ex) {
throw new RuntimeException("error getting data source credential value : " + path.toString(), ex);
}
}
@Override
@Bean
public R2dbcCustomConversions r2dbcCustomConversions() {
List<Converter<?, ?>> converterList = new ArrayList<>();
converterList.add(movieReadConverter);
return new R2dbcCustomConversions(getStoreConversions(), converterList);
}
@Override
@Bean
public ConnectionFactory connectionFactory() {
Map<String, String> options = new HashMap<>();
options.put("default_transaction_read_only", dataSourceProperties.getReadOnly().toString());
return ConnectionFactories.get(ConnectionFactoryOptions.builder()
.option(PROTOCOL, dataSourceProperties.getProtocol())
.option(DRIVER, POOLING_DRIVER)
.option(HOST, dataSourceProperties.getHost())
.option(PORT, dataSourceProperties.getPort())
.option(USER, userName)
.option(PASSWORD, password)
.option(SSL, true)
.option(Option.valueOf("sslMode"), "allow")
.option(DATABASE, dataSourceProperties.getDatabase())
.option(INITIAL_SIZE, dataSourceProperties.getPool().getMinConnections())
.option(MAX_SIZE, dataSourceProperties.getPool().getMaxConnections())
.option(VALIDATION_QUERY, "SELECT 1")
.option(Option.valueOf("options"), options)
.build());
}
}This is how setup a connection to our database with a connection pool and set our converter.
Creating our Routes
We wil continue creating our router
package org.learning.by.example.movies.springwebflux.router;
import org.learning.by.example.movies.springwebflux.handler.MovieHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.config.EnableWebFlux;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.ServerResponse;
import static org.springframework.web.reactive.function.server.RequestPredicates.GET;
import static org.springframework.web.reactive.function.server.RouterFunctions.route;
@Component
@EnableWebFlux
public class MovieRouter {
final MovieHandler movieHandler;
public MovieRouter(final MovieHandler movieHandler) {
this.movieHandler = movieHandler;
}
@Bean
RouterFunction<ServerResponse> movies() {
return route(GET("/movies/{genre}"), movieHandler::getMovies);
}
}As we could see this is a simple RouterFunction for our /movies/genre URL.
Next will be the handler.
package org.learning.by.example.movies.springwebflux.handler;
import org.learning.by.example.movies.springwebflux.model.Movie;
import org.learning.by.example.movies.springwebflux.repositories.MoviesRepository;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.server.ServerRequest;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@Component
public class MovieHandler {
final MoviesRepository moviesRepository;
public MovieHandler(final MoviesRepository moviesRepository) {
this.moviesRepository = moviesRepository;
}
public Mono<ServerResponse> getMovies(final ServerRequest request) {
final String genre = request.pathVariable("genre");
final Flux<Movie> movies = moviesRepository.findByGenre(genre.toLowerCase());
return ServerResponse.ok().body(movies, Movie.class);
}
}The handler is using the repository to retrieve the movies and return the response back to the router.
Finally we will setup our configuration in our application.yml
movies-datasource:
protocol: "postgresql"
host: "${MOVIES_DB_CLUSTER_SERVICE_HOST}"
port: ${MOVIES_DB_CLUSTER_SERVICE_PORT_POSTGRESQL}
database: "movies"
credentials: "/etc/movies-db"
read-only: true
pool:
min-connections: 1
max-connections: 3
logging:
level:
ROOT: ERROR
spring:
main:
banner-mode: off
jmx:
enabled: falseConfiguring our deployment
First we will copy our Dockerfile, deployment.yml, JMeter scripts and bash scripts for our previous example and rename movies-spring-web to movies-spring-webflux on them.
Them we will modify our deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: movies-spring-webflux
name: movies-spring-webflux
spec:
replicas: 1
selector:
matchLabels:
app: movies-spring-webflux
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: movies-spring-webflux
spec:
containers:
- image: localhost:32000/movies-spring-webflux:0.0.1
imagePullPolicy: Always
name: movies-spring-webflux
resources: {}
env:
- name: "JAVA_OPTS"
value: >-
-XX:+UseParallelGC
-Xms100m
-Xmx325m
--add-opens java.base/jdk.internal.misc=ALL-UNNAMED
--add-opens java.base/java.nio=ALL-UNNAMED
--add-exports java.base/jdk.internal.misc=ALL-UNNAMED
-Dio.netty.tryReflectionSetAccessible=true
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
livenessProbe:
httpGet:
path: /actuator/info
port: 8080
volumeMounts:
- name: db-credentials
mountPath: "/etc/movies-db"
readOnly: true
- name: tmp
mountPath: "/tmp"
readOnly: false
volumes:
- name: db-credentials
secret:
secretName: moviesuser.movies-db-cluster.credentials
- name: tmp
emptyDir: {}
status: {}
---
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: movies-spring-webflux
name: movies-spring-webflux
spec:
ports:
- name: 8080-8080
port: 8080
protocol: TCP
targetPort: 8080
selector:
app: movies-spring-webflux
type: ClusterIP
status:
loadBalancer: {}We are setting up additional JAVA_OPTS that are require to use native buffers in Netty on Java 9+.
Them we will edit our jlink.sh script to include an additional module :
#!/bin/sh -
set -o errexit
BASE_DIR="$(
cd "$(dirname "$0")"
pwd -P
)"
DEPS_DIR="$BASE_DIR/deps"
mkdir -p "$DEPS_DIR"
echo "extracting jar"
cd "$DEPS_DIR"
jar -xf ../*.jar
echo "jar extracted"
echo "generate JVM modules list"
EX_JVM_DEPS="jdk.crypto.ec,jdk.unsupported"
JVM_DEPS=$(jdeps -s --multi-release 11 -recursive -cp BOOT-INF/lib/*.jar BOOT-INF/classes | \
grep -Po '(java|jdk)\..*' | \
sort -u | \
tr '\n' ',')
MODULES="$JVM_DEPS$EX_JVM_DEPS"
echo "$MODULES"
echo "JVM modules list generated"
echo "doing jlink"
jlink \
--verbose \
--module-path "$JAVA_HOME/jmods", \
--add-modules "$MODULES" \
--compress 2 \
--no-header-files \
--no-man-pages \
--strip-debug \
--output "$DEPS_DIR/jre-jlink"
echo "jlink done"
cd "$BASE_DIR"Finally we could build and deploy our application :
$ ./build.sh
$ ./deploy.shRunning the complete set
With this we are ready to run our final test following the procedure that we stablish in the first part of the series, and we will get this numbers :
| C. Users | Pods | ART | TPS | Max CPU | Max MEM | Service |
|---|---|---|---|---|---|---|
| 1 | 1 | 39.16 | 25.49 | 403 | 474 | 01 Base |
| 1 | 1 | 34.61 | 28.85 | 209 | 252 | 02 Spring Web |
| 1 | 1 | 31.21 | 31.99 | 335 | 310 | 03 Spring WebFlux |
| 10 | 1 | 570.47 | 16.73 | 916 | 487 | 01 Base |
| 10 | 1 | 111.61 | 85.53 | 350 | 626 | 02 Spring Web |
| 10 | 1 | 100.93 | 94.59 | 1036 | 355 | 03 Spring WebFlux |
| 25 | 3 | 1615.82 | 14.72 | 1049 | 1454 | 01 Base |
| 25 | 1 | 266.03 | 89.44 | 686 | 369 | 02 Spring Web |
| 25 | 1 | 368.0 | 76.33 | 1046 | 511 | 03 Spring WebFlux |
| 50 | 5 | 3190.98 | 14.89 | 1351 | 2499 | 01 Base |
| 50 | 3 | 1982.03 | 23.95 | 774 | 1060 | 02 Spring Web |
| 50 | 1 | 631.65 | 75.24 | 1063 | 515 | 03 Spring WebFlux |
01 Base = Java 8 - Spring Boot 2.2.2 - Spring Web - Spring Data JDBC default settings, unoptimized
02 Spring Web = Java 11 - Spring Boot 2.2.2 - Spring Web - Spring Data JDBC optimized
03 Spring WebFlux = Java 11 - Spring Boot 2.2.4 - Spring WebFlux - Spring Data R2DBC optimized
Conclusions
As we could see the performance of the reactive solution is great, we could even handle 50 concurrent users with just one Pod, and that is because we are not so bound to threads in this implementation.
However we could see that with 25 concurrent users we are not doing so great, and that is probably because we setup very a very small heap and the GC is cleaning more often that it should, but I’ve setup this to minimize memory consumption, we could increase a bit the heap this will cause less GC runs, better ART but more MEM usage, and this is key in our overall optimization strategy, if we care more about ART of use of MEM.
Finally, Spring Data R2DBC still on experimental stage, numbers will change with future relases.
Note: The full code of this service is available at this repository.
Resources